
Disse services kan både købes som et tilvalg til Insight Tools og FilArkiv – eller som selvstændige services!

Gør tekster i PDF’er søgbare ved hjælp af optisk tegngenkendelse. Læs mere

Søg og rens PDF-dokumenter for personfølsomme oplysninger. Læs mere

Sikker signering af PDF-filer med digital signatur. Læs mere
OCR (Optical Character Recognition) er en digital teknologi, der bruges til at aflæse trykte eller skrevne bogstaver, tal og tegn.
Med vores OCR-løsning kan du spare meget tid og undgå ekstra licensomkostninger, når du skal konvertere scannede dokumenter eller søge efter følsomme oplysninger i PDF-dokumenter.
Optimeret til danske forhold. Derfor får du højeste kvalitet, når det gælder genkendelse af danske bogstaver og specialtegn.
OCR-fortolkeren er avanceret og kan analysere enkeltsider og distribuere opgaven ud til flere cpu-kerner på flere servere, hvis dette skulle blive nødvendigt. Det giver ekstremt hurtige svartider selv ved meget store dokumenter.
Når det gælder software til dokumenthåndtering og OCR-fortolkning, anvender vi kun de bedste software-komponenter fra de bedste udbydere. Komponenterne bliver testet og installeret i vores egen infrastruktur, og vi garanterer, at tjenesterne løbende bliver opdateret med de seneste forbedringer og ny funktionalitet.
FilArkiv Online OCR er udviklet til at overholde høje sikkerhedskrav. Eksempelvis er tjenestens servere placeret i to professionelle hosting centre i Danmark, og al kommunikation mellem klient og servere sker krypteret.
Vi skræddersyr en serviceaftale med tilhørende SLA, der passer netop til jeres behov. Der vil altid være forskellige krav og ønsker i forhold til brug af tjenester af denne art. Nogle brugere ønsker at køre batch-konvertering og OCR-fortolkning med lav prioritet over-night, mens andre ønsker hurtige svartider i dagtimerne, når der eksempelvis er en brugerinteraktion involveret i processen.


PDF-indholdsblokker er en ny unik softwareløsning fra JO Informatik, der gør det væsentligt nemmere for kommuner og private virksomheder fx at efterleve GDPR-lovgivningen, når borgere, virksomheder og andre myndigheder downloader PDF-dokumenter fra internettet.
Screening og rensning i realtid af alle PDF-dokumenter, der bliver downloadet - uden at ændre i originaludgaver af dokumenterne.
Nem integration til løsninger fra andre leverandører.
PDF-indholdsblokker er en cloudbaseret webservice, der ikke kræver installation.
Klik her for at se et PDF-dokument fra et byggesagsarkiv, der har været screenet i PDF-indholdsblokker.
PDF-indholdsblokker bliver løbende forbedret med de nyeste teknologier såsom maskinlæring (ML) og kunstig intelligens (AI).
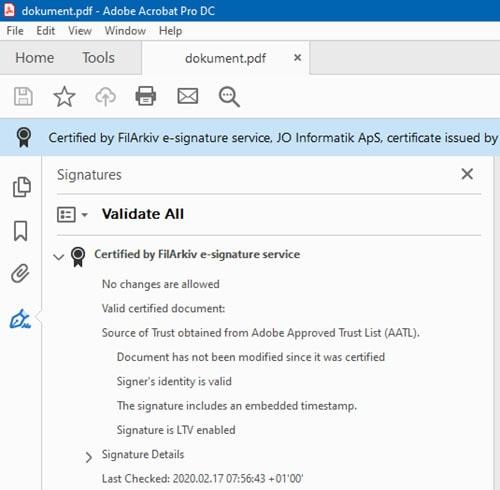
I en PDF-signering stemples PDF-filer med en digital signatur. Signaturen kan anvendes til at afgøre, om indholdet i PDF-filen er uændret i forhold til signeringstidspunktet af PDF-filen. Hvis der ændres blot en enkelt bit i PDF-filen, vil signaturen optræde som ugyldig, og læseren vil få en tydelig advarsel.
Signaturen er af typen Long-Term Validation (LTV), hvilket sikrer, at signerede PDF-dokumenter også kan valideres mange år ude i fremtiden.
Vi tilbyder individuelle profilopsætninger, hvor du får indflydelse på afsendernavn (firmanavn) og anden identifikation i den digitale signatur.
Her er et udvalg af de 54 danske og 3 norske kommuner, som vi hjælper med arkivløsninger og datasikkerhed.